Memory Hierarchy
#lecture note based on 15-213 Introduction to Computer Systems
H2 Overview
For many years, hardwares are optimised with some memory hierarchy and software designed to use them.
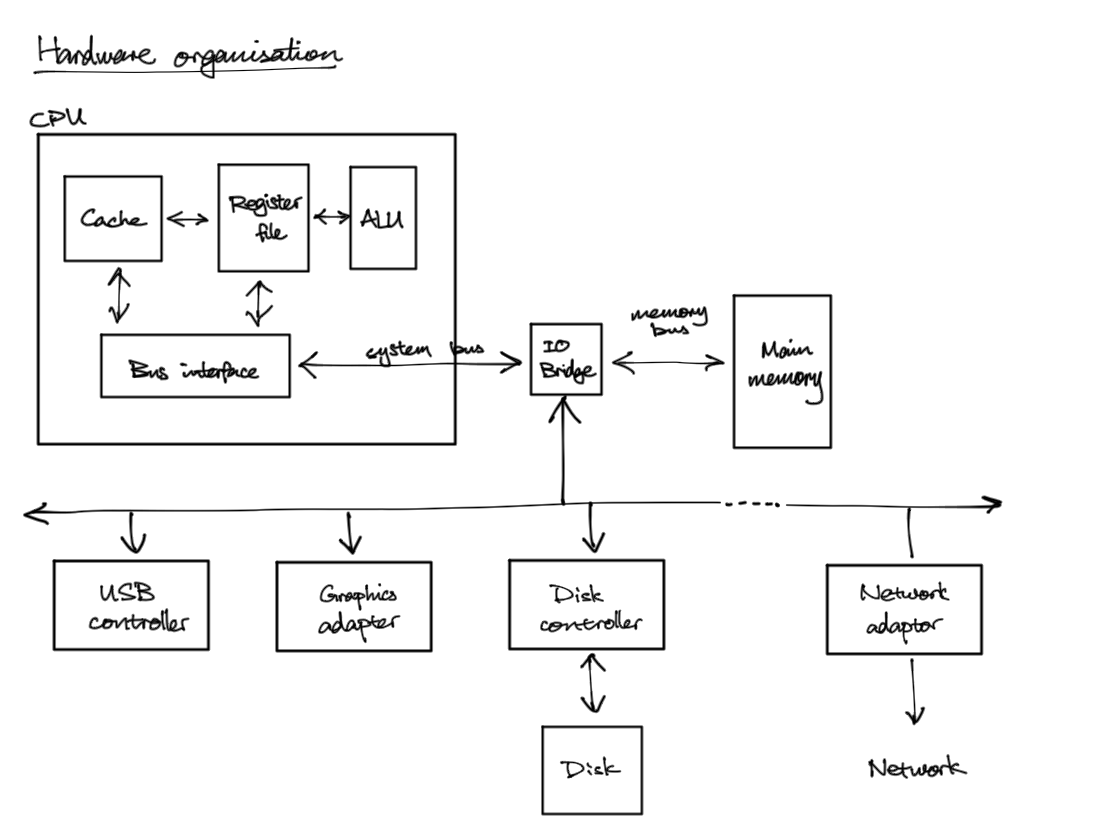
- ALU - does arithmetics
- bus - some wires to carry address, data, and control signal
- memory controller - links register to main memory
- write: takes address and data
- read: takes address and returns to register
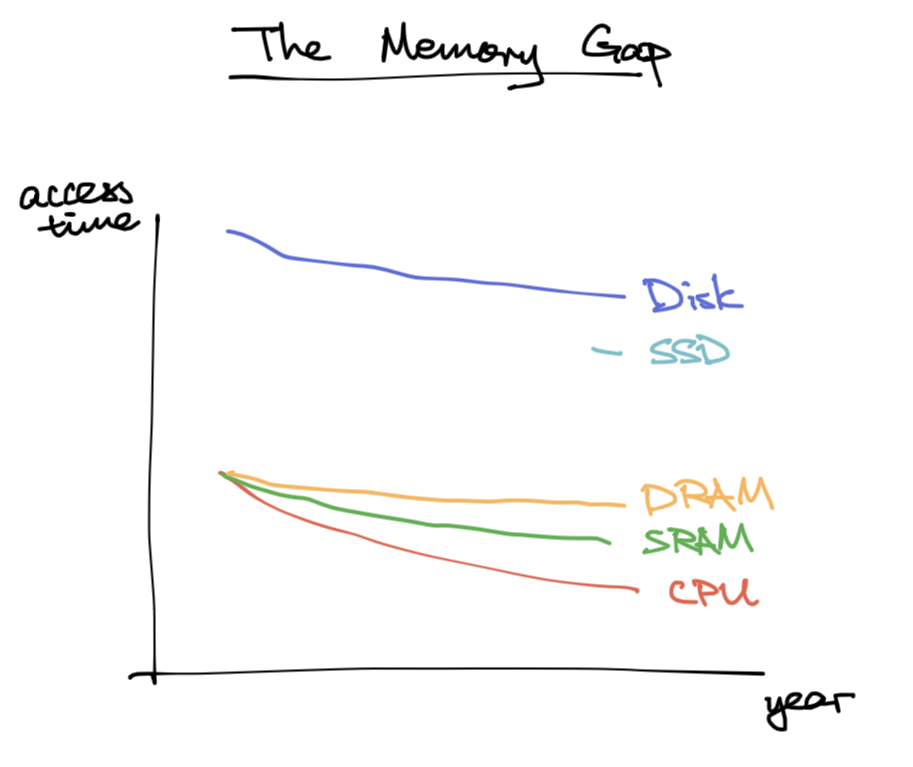
The memory gap: CPU used to be as fast as memory, but it got much faster than memory, so waiting for memory would bottleneck CPU throughput.
H2 Random Access Memory (RAM)
Random - access memory with no particular pattern
Types of RAM (names don’t make much sense):
- DRAM (Dynamic) - 1 transister + 1 capacitor per bit. Capacitor leaks, must refresh (read and write back in) periodically to keep the data.
- Slower (about 10x)
- Cheaper
- Useful for main memory
- SRAM (Static) - 6 transisters per bit. Holds state as long as there’s power (the transisters pass bits to each other in a loop)
- Faster
- More expensive (about 100x)
- Useful for cache memory
H2 Locality of Reference
History - DRAM, SRAM, and CPU ran at same speed.
Now - CPU faster than SRAM, SRAM faster than DRAM.
Problem: there’s a gap between memory access and cpu speed.
Solution: locality - use data & instructions that are close to each other.
Types of locality
- Temporal locality - recently used data likely to be used in near future
- Spatial locality - likely to use data close to recently used data
H2 The Hierarchy
Motivation: tradeoff between speed, cost, and capacity
| level | |
|---|---|
| L0 | rigisters |
| L1 | L1 cache SRAM |
| L2 | L2 cache SRAM |
| L3 | L3 cache SRAM |
| L4 | Main meory DRAM |
| L5 | disk |
| L6 | remote storage |
$ sounds like cash so they decided to use it for cache. (Nothing to do with $ for constants in x86 assembly)
Things with higher locality move up the memory hierarchy.
H2 Data transfer between caches
- Generally an order of magnitude speed difference
- Data managed in block size units
- Upper cache holds subset of blocks
- When access:
- if not found in higher, miss, replace some block
- placement policy - where the missing block goes
- replacement policy - which existing block get replaced (victim)
- if found, hit, go no further down the hierarchy.
- if not found in higher, miss, replace some block
H3 Types of Cache misses
- Cold (compulsory) miss - miss because never accessed this before
- Capacity miss - when set of things currently in access is larger than cache size. E.g. cache has 4 blocks but working with 5 blocks.
- Conflict miss - sometimes position A at level k+1 can only hold a subset of positions from level k. So when multiple blocks that require position A in level k needs to be accessed, there must be conflict miss at k+1.
- Better placement policy may help with this (but could also make it harder to search for cache)
- goes away if we increase E associative value
- viz. when capacity of the whole cache is enough but the working blocks map to same set
- (Miss due to update in another cache in multicore execution)
H3 Checking if something is in cache
It becomes harder to find if there are lots of things in cache.
Placement policy hints search space.
H2 Cache Memory
Usually some small, fast SRAM managed by hardware.
H3 Cache organisation
Identified using 4 different values (know 3 is sufficient)
- S - sets - placement location. Every given block maps to a single set
- E - lines per set - how many blocks can be in a set (not necessarily power of 2 but for simplicity suppose it is)
- B - block size - the data
- C - capacity (ECE likes to use this) - equals
S * E * B
S, B need to be power of 2.
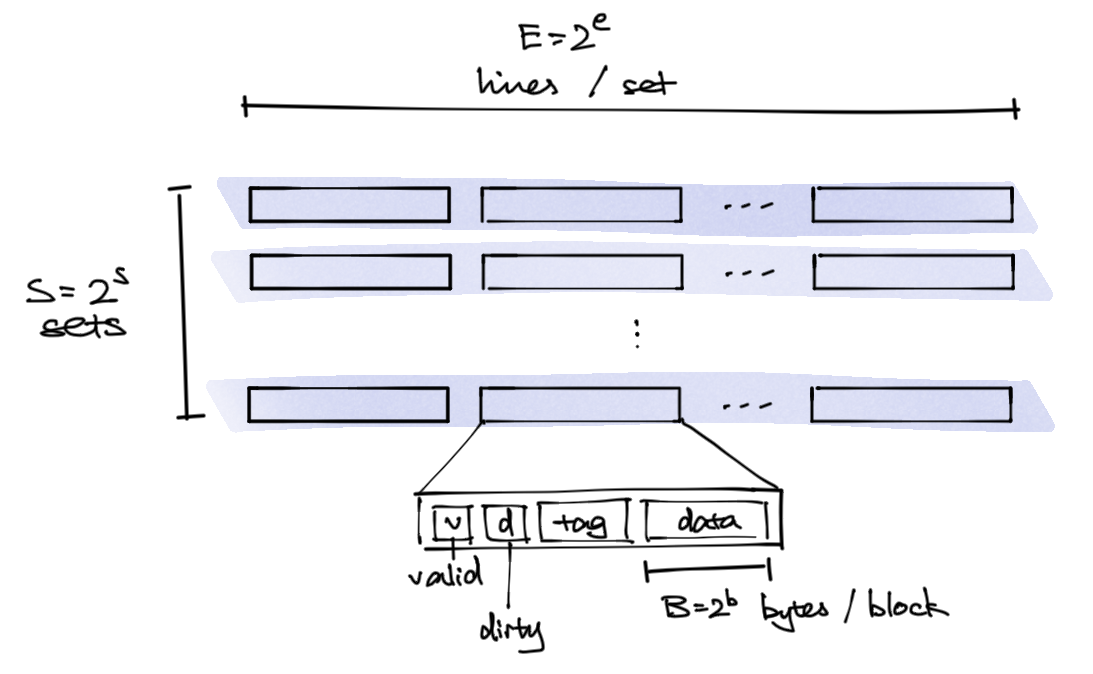
Example: say we have 4-bit addresses (M = 16 byte), S = 4, E = 1, B = 2, then an address looks like 1011 where <tag><set><set><bit>. 1 bit is needed to identify the byte location within block, two to specify the set, and the rest go as tag.
Each line has:
- valid bit
v - dirty bit
- tag
- the block, storing the data
Address <tag><set index><block offset>:
- tag, t bits - to match the tag in cache. If match it’s a hit
- set index, s bit - to identify which set the block goes
- block offset, b bits - to select bits in a block upon hit
Mapping:
- direct - when E = 1, so each block can only go to 1 place
- E-way associative - each block can end up in E places
H3 Writes
- Write-through - write immediately to memory
- write-back - defer write until line replacement, so hold in cache instead of writing to memory
Extra line in block: extra dirty d bit to keep track of if something wrote to it.
Oh hit: write the bits, turn on dirty bit
Oh miss:
- write-allocate - load into cache update line in cache. viz treat as read miss
- no-write-allocate - write to memory, no load into cache
Typically: write-back + write-allocate
Less typical: write-through + no-write-allocate
Dirty bit is sticky - only cleared and transfer back on eviction
H3 Some replacement policies
Ideally: remove the one least likely to be used in future
- least recently used (LRU) - (assumses they remain least recently used)
- random
- least frequently used
- first in first out
H3 Performance metric
- Miss rate
- Usually 3-10% for L1
- Usually 1% for L2
- Hit time - design dependent
- 4 cycles for L1
- 10 cycles for L2
- miss penalty - cost if miss
- 50-200 cycles for main memory
- Average access time =
hit time + miss rate * miss panalty
H3 The Memory Mountain
Throughput based on size and stride (distance between memory accesses) - cover of CS:APP.
Prefetching - hardware predicting future access if it sees pattern.
Blocking - break access into smaller chunks that can fit inside cache at the same time - helps with temporal locality.
H3 Code optimisation with cache
Good practices:
- Try to maximise hit rate of inner most loop
- Try to have good locality
- Try to minimise eviction
- Blocking together nearby accesses
H3 Cache coherence
Coherent if you can write down some serial order and
- same ord within proc
- write -> read causality (maybe 1-2 cycles tolerated)
Directory way
- put cache state in directory (e.g. bitmap for what procs they are present on + dirty bit), lookup when needed, try only use p2p comm
- directory can be distributed, at where its mem is located. for p to access thing in another proc’s mem, request p’, and p’ mark the bit
- if requesting a dirty line present on another proc, return id of proc currently owning that line. the once owner also needs to tell directory on home node to update
- write miss sth shared: request it, get back sharer ids, ask sharers to invalidate, wait for ack
Space Opts:
- limited pointer: like storing only 1, 2, 3, everyone
- sparse directory: use doubly linked list with extra data (point from home directory, then a chain of nodes having the cache), a bit like malloc lab
Num msg opts:
- forwarding: home ask p’ to invalidate, p’ gives data back, home passes data back to p that requested to write. even better, p’ sends to p and home at same time