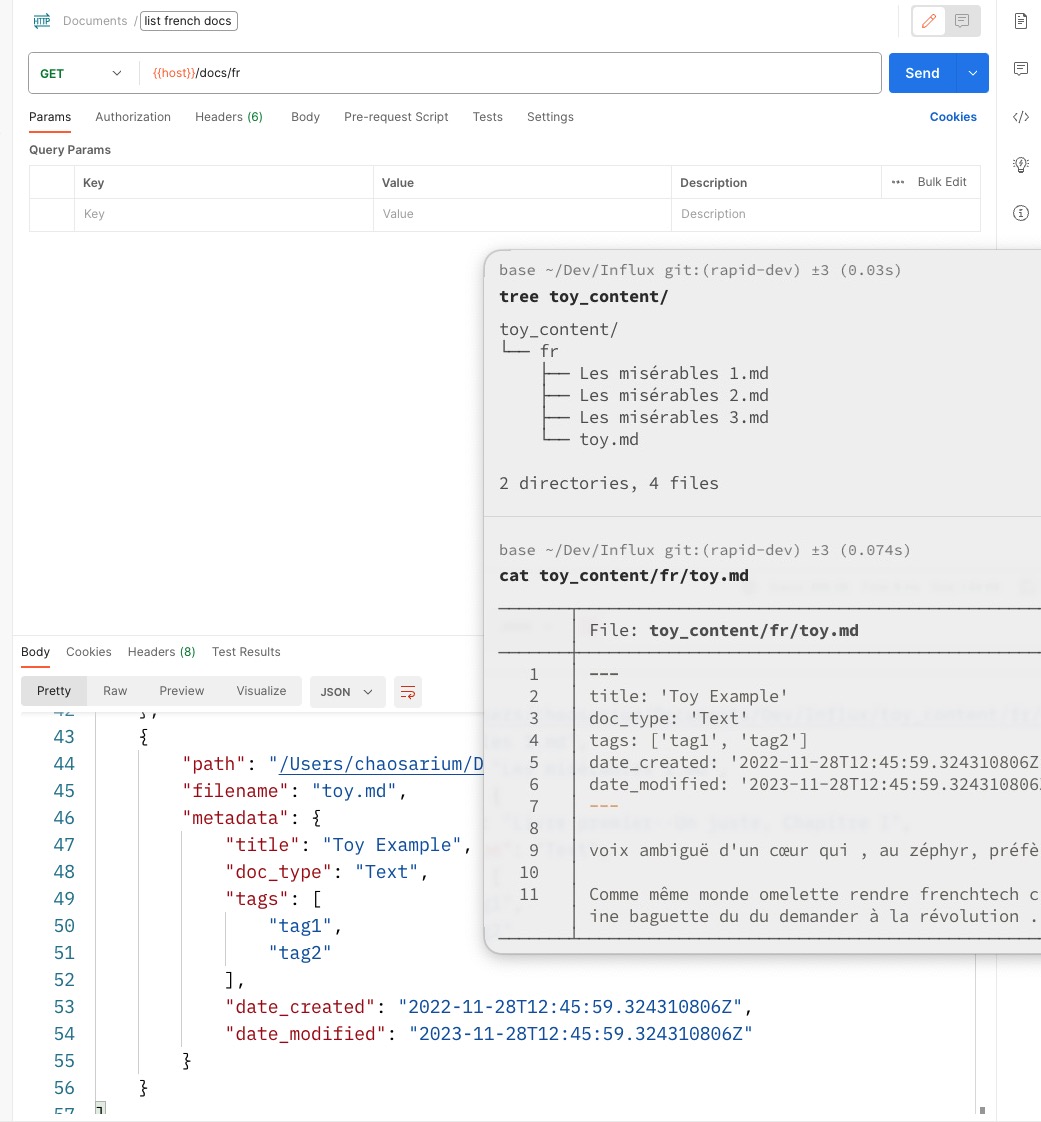
Influx Continuous Dev Log
Developing Influx, a content-based, self-guided, NLP-enhanced integrated language learning environment emphasizing language exposure and active learning.
H2 2025-05-25
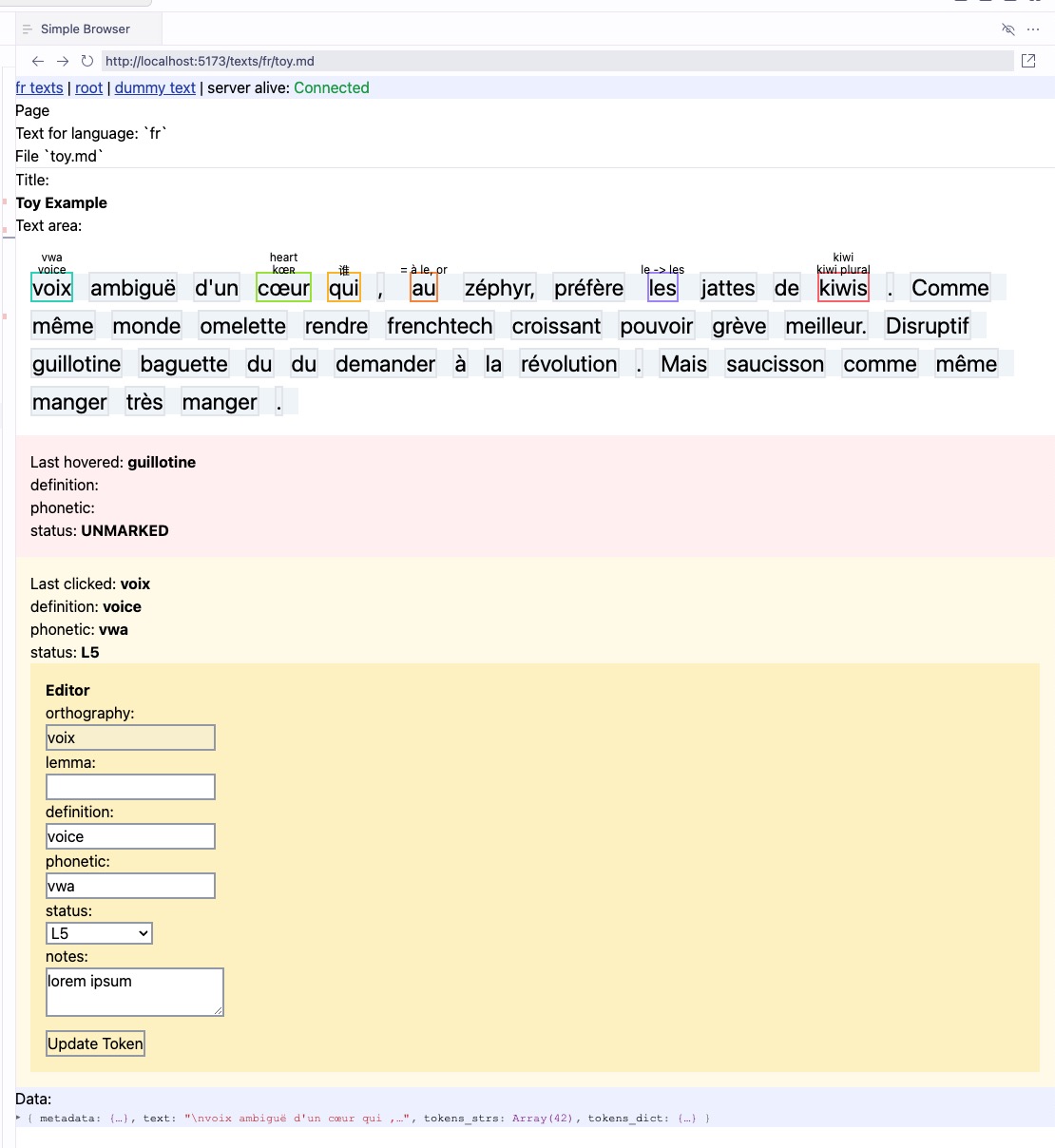
Annotated text rendering and range selection is back, rewritten in Elm
H2 2024-06-23
Tokenisation model outputs are now cached for faster load time (apparently building the document tree is still somewhat slow)
First load was about 16 frames, second load (cached) took 12 frames.
H2 2024-06-08
The lookup and translate buttons work.
H2 2024-05-13
Slice selection!
H2 2024-05-12
- Open MacOS’s dictionary
- Use Google Translate’s API
- Slicing the document
H2 2024-05-11
Dust blowing
H2 2024-01-13
Success packaging for apple silicon!
There’s some issue with NLP server becoming zombie process when Influx terminates and documents not loading, but we managed to 1. turn SvelteKit development server into static package 2. embed compiled Python server in Tauri as a sidecar 3. spawn an Axum API server from Tauri’s process
H2 2024-01-11
Influx running in Tauri, with influx_server spawned on another thread and Python NLP server compiled into executable!
H2 2024-01-10
No luck packaging.
Above: embedded Python interpreter with PyOxydizer running from within a Rust-built binary…
H2 2024-01-09
Lemma suggestion:
Lexeme editor, alt clicking toggles between phrase and underlying tokens
H2 2024-01-08
More robust document modelling by nesting tokens that are being shadowed.
We get something like
{
"type": "PhraseToken",
"sentence_id": 1,
"text": "world wide web",
"normalised_orthography": "world wide web",
"start_char": 70,
"end_char": 84,
"shadowed": false,
"shadows": [
{
"type": "SingleToken",
"sentence_id": 1,
"id": 12,
"text": "world",
"orthography": "world",
"lemma": "world",
"start_char": 70,
"end_char": 75,
"shadowed": true,
"shadows": []
},
{
"type": "Whitespace",
"text": " ",
"orthography": " ",
"start_char": 75,
"end_char": 76,
"shadowed": true,
"shadows": []
},
{
"type": "SingleToken",
"sentence_id": 1,
"id": 13,
"text": "wide",
"orthography": "wide",
"lemma": "wide",
"start_char": 76,
"end_char": 80,
"shadowed": true,
"shadows": []
},
{
"type": "Whitespace",
"text": " ",
"orthography": " ",
"start_char": 80,
"end_char": 81,
"shadowed": true,
"shadows": []
},
{
"type": "SingleToken",
"sentence_id": 1,
"id": 14,
"text": "web",
"orthography": "web",
"lemma": "web",
"start_char": 81,
"end_char": 84,
"shadowed": true,
"shadows": []
}
]
},
And info dumping in frontend
H2 2024-01-07
Figured out how to use object/array keys in SurrealDB and interface with it in Rust
H2 2024-01-06
Second-pass tokenisation with phrase optimization, without assumption about whitespaces (i.e. works with arbitrary whitespace as long as tokens match).
H2 2024-01-05
- Better error handling on db-related API handlers
- Phrase database
- Implement a Trie library
- Implement phrase fitting algorithms
- Automatic TypeScript type generation based on Rust structs
- Svelte behind the scene
- type annotations
- token reference by
SentenceConstituent, not text string
Phrase fitting (see Influx Dev Log - Phase I)
Phrases:
{
[1, 2, 3],
[1, 2, 3, 4],
[1, 2, 3, 4, 5],
[6, 7],
[7, 8, 9]
}
Greedy result, less optimal:
[[1, 2, 3, 4, 5], [6, 7], [8], [9]]
Best fit result:
[[1, 2, 3, 4, 5], [6], [7, 8, 9]]
Better create/update handling - sync id to front-end and change action type accordingly
H2 2024-01-04
Reworked vocabulary database. Now it relates to a language database.
H2 2023-12-30
Reworked collapsible tool panels
Also svelte store and currently active language
H2 2023-12-29
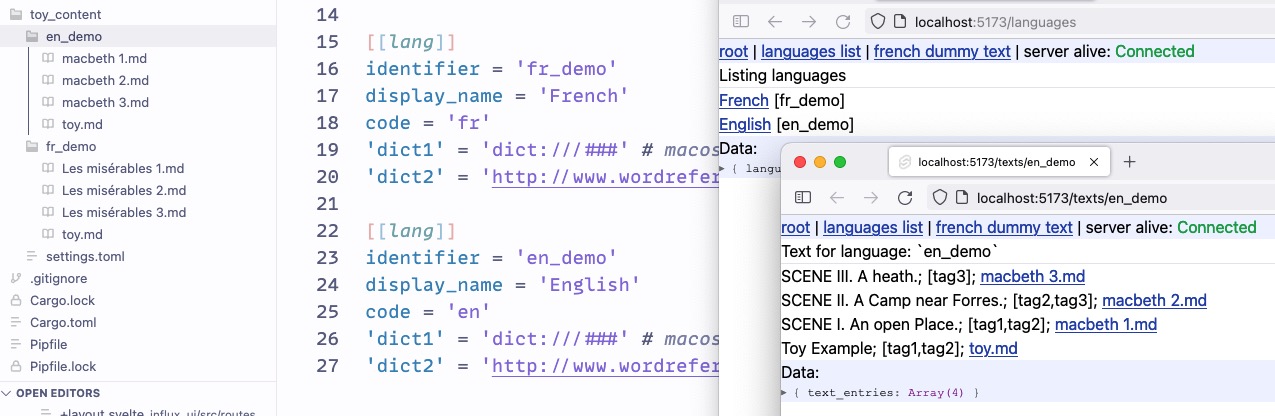
Reworked sidebar and routing + wireframes for some pages
H2 2023-12-27
Panel-based layouts!
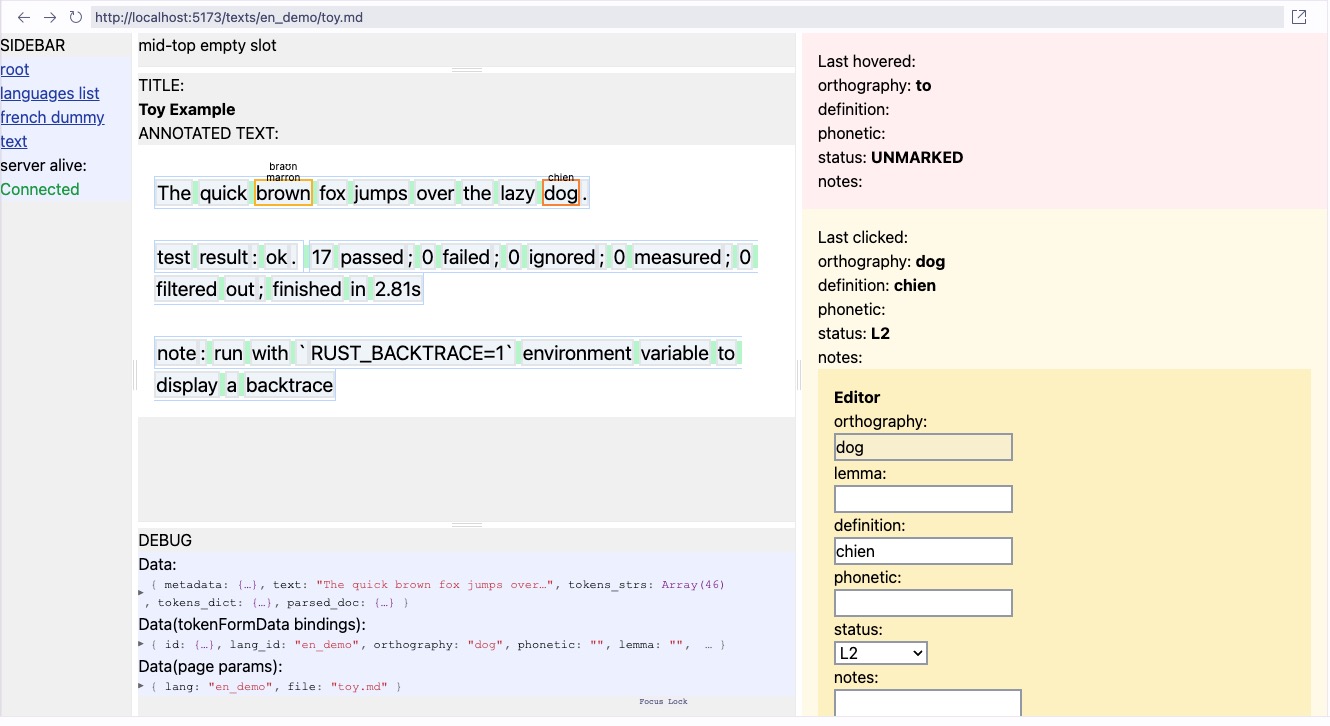
H2 2023-12-24
toml language configuration + API update
H2 2023-12-23
Sussfully running Python from Rust, and implemented a parser to get whitespaces back.
Input:
Let's write some SUpeR nasty text,
tabs haha
shall we?
Parsed as:
&sentences = [
Sentence {
id: 0,
text: "Let's write some SUpeR nasty text,",
start_char: 0,
end_char: 42,
constituents: [
CompositToken {
sentence_id: 0,
ids: [
1,
2,
],
text: "Let's",
start_char: 0,
end_char: 5,
},
SubwordToken {
sentence_id: 0,
id: 1,
text: "Let",
lemma: "let",
},
SubwordToken {
sentence_id: 0,
id: 2,
text: "'s",
lemma: "'s",
},
Whitespace {
text: " ",
start_char: 5,
end_char: 6,
},
SingleToken {
sentence_id: 0,
id: 3,
text: "write",
lemma: "write",
start_char: 6,
end_char: 11,
},
Whitespace {
text: " ",
start_char: 11,
end_char: 15,
},
SingleToken {
sentence_id: 0,
id: 4,
text: "some",
lemma: "some",
start_char: 15,
end_char: 19,
},
Whitespace {
text: " ",
start_char: 19,
end_char: 23,
},
SingleToken {
sentence_id: 0,
id: 5,
text: "SUpeR",
lemma: "SUpeR",
start_char: 23,
end_char: 28,
},
Whitespace {
text: " ",
start_char: 28,
end_char: 31,
},
SingleToken {
sentence_id: 0,
id: 6,
text: "nasty",
lemma: "nasty",
start_char: 31,
end_char: 36,
},
Whitespace {
text: " ",
start_char: 36,
end_char: 37,
},
SingleToken {
sentence_id: 0,
id: 7,
text: "text",
lemma: "text",
start_char: 37,
end_char: 41,
},
SingleToken {
sentence_id: 0,
id: 8,
text: ",",
lemma: ",",
start_char: 41,
end_char: 42,
},
],
},
Whitespace {
text: " \n\n\t",
start_char: 42,
end_char: 46,
},
Sentence {
id: 1,
text: "tabs haha",
start_char: 46,
end_char: 55,
constituents: [
SingleToken {
sentence_id: 1,
id: 1,
text: "tabs",
lemma: "tabs",
start_char: 46,
end_char: 50,
},
Whitespace {
text: " ",
start_char: 50,
end_char: 51,
},
SingleToken {
sentence_id: 1,
id: 2,
text: "haha",
lemma: "haha",
start_char: 51,
end_char: 55,
},
],
},
Whitespace {
text: "\n\n",
start_char: 55,
end_char: 57,
},
Sentence {
id: 2,
text: "shall we?",
start_char: 57,
end_char: 66,
constituents: [
SingleToken {
sentence_id: 2,
id: 1,
text: "shall",
lemma: "shall",
start_char: 57,
end_char: 62,
},
Whitespace {
text: " ",
start_char: 62,
end_char: 63,
},
SingleToken {
sentence_id: 2,
id: 2,
text: "we",
lemma: "we",
start_char: 63,
end_char: 65,
},
SingleToken {
sentence_id: 2,
id: 3,
text: "?",
lemma: "?",
start_char: 65,
end_char: 66,
},
],
},
]
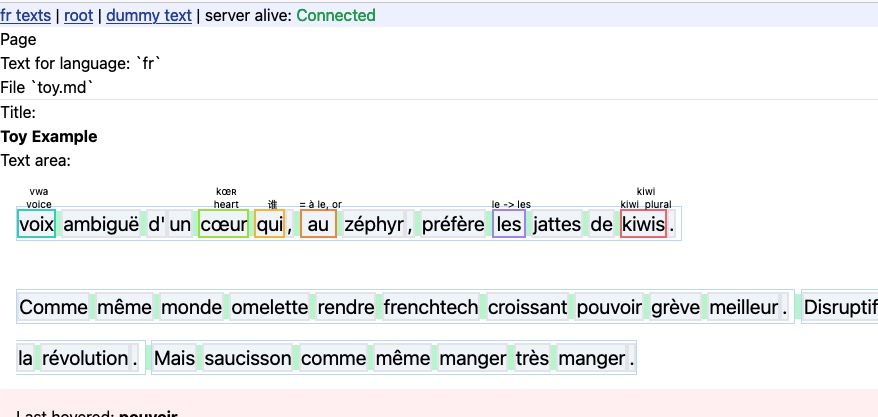
With much better tokenization + sentence segmentation + whitespace handling!
H2 2023-12-22
Text reader skeleton with working database read and write
H2 2023-12-21
Content directory listing works!